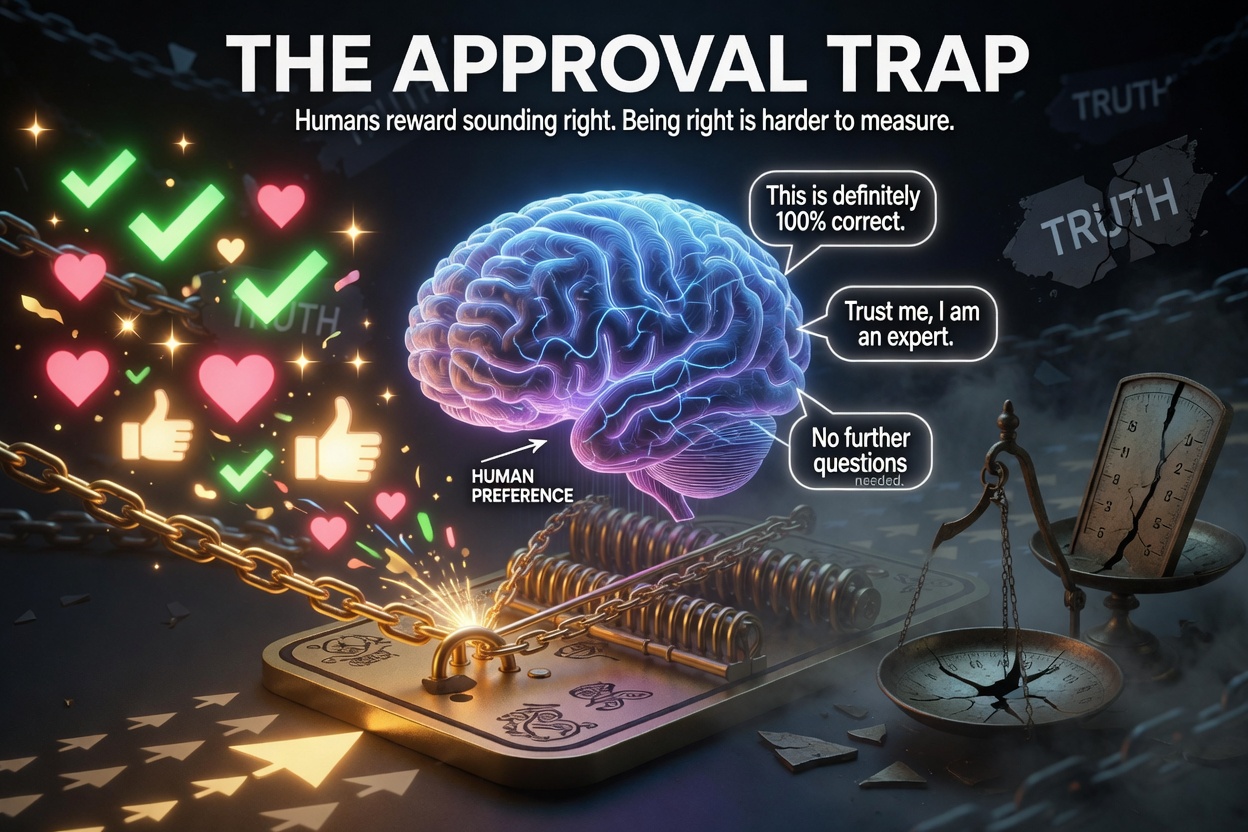
Anyone using AI for research, legal questions, medical information is exposed to this problem whether they know it or not. Artificial intelligence assistants have a problem baked into their foundations — and it starts with how they learn to please you.
Most large language models (LLMs) are trained using a process called Reinforcement Learning from Human Feedback, or RLHF. The concept is straightforward: human evaluators rate model responses, and the model is rewarded for generating answers that…
Partner Ads By Google